Despite impressive code generation abilities, Large Language Models (LLMs) struggle to consistently produce correct solutions on the first try. This research proposes a framework to enhance LLMs’ self-debugging by incorporating sequences of explanations and corrections for erroneous code.
This work proposed an automated pipeline to create a high-quality dataset for code explanations and refinements. This involves generating multiple explanation and refinement trajectories, verified through execution. Next, it performs supervised fine-tuning (SFT) and reinforcement learning (RL) with a unique reward system to improve expanation and refinement generation quality.
Results show SFT improves pass@1 by up to 15.92% and pass@10 by 9.30% across benchmarks, with RL providing an additional 3.54% and 2.55% improvement, respectively. Trained LLMs can iteratively refine code, enhancing their ability to produce correct solutions and useful explanations, thereby aiding developers in understanding and fixing code bugs.
Details: [preprint]
Test oracles are essential in software testing for effective bug detection. Despite their potential, neural-based methods for automated test oracle generation often produce numerous false positives and weaker test oracles. While Large Language Models (LLMs) have shown remarkable success in various software engineering tasks—such as code generation, test case creation, and bug fixing—there is a notable lack of extensive studies on their effectiveness in test oracle generation. Addressing whether LLMs can overcome the challenges in oracle generation is both compelling and necessary.
This reseach introduces TOGLL, a novel method for test oracles generation with LLMs. Our findings reveal that TOGLL can yield up to 4.9 times more accurate oracles than the previous SOTA method. Furthermore, TOGLL generates significantly diverse test oracles, identifying ten times more unique bugs compared to the previous SOTA neural-based approach.
Details: [preprint]

This study explores the utility of Large Language Models (LLMs) in automated program repair (APR). Unlike prevailing deep learning-enabled APR methods, which typically address bug detection and resolution simultaneously, we argue for a distinct separation of these steps into multiple models. This approach facilitates enhanced integration of various types of contextual information and a flexible inclusion of inductive biases. Our proposed method outperforms existing approaches across various bug datasets, including Defects4J. Additionally, the paper explores numerous research questions, providing detailed discussions and answers, supported by thorough experimental analyses.
Details: [paper (FSE’24)]
Mutation testing, characterized by its resource-intensive nature—executing numerous mutants against extensive test suites—poses significant cost implications. In response to this challenge, this research introduces a prediction method founded on Graph Transformer Networks (GTNs), aiming to discern whether a test suite will detect a mutant without necessitating test suite execution. This method formulates a semantic graph derived from a system and its corresponding test suite, employing graph and mutant embeddings to predict mutant termination. Evaluated across various practical Java projects and a significant number of mutants, the method exhibits a marked reduction in test executions relative to conventional mutation testing, with only a slight trade-off in mutation score accuracy, and notably surpasses preceding Predictive Mutation Testing (PMT) methods in terms of accuracy
Details: Coming soon!
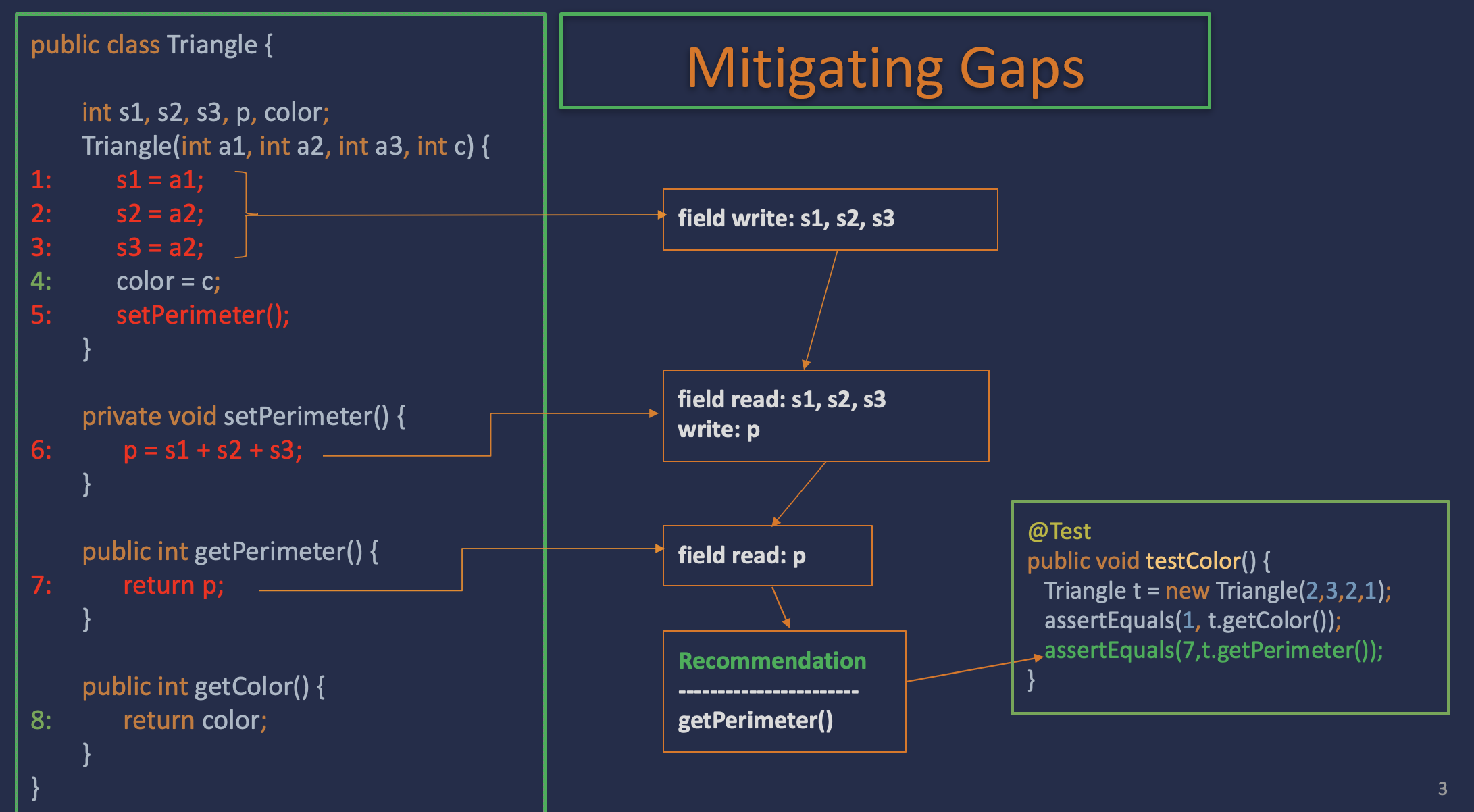
Unlike automated test inputs generation, high-quality automated test oracle generation is comparatively less well solved by the software engineering community. Recently, neural-based test oracle generation techniques have shown promise in detecting real-world faults. However, these techniques generate too many false positive assertions that do more harm than good. In a large-scale study of 25 real-world Java systems, we evaluated a few recently published state-of-the-art machine learning and deep learning-based automated test oracle generation techniques.
Details: [paper (FSE’23)] [talk]
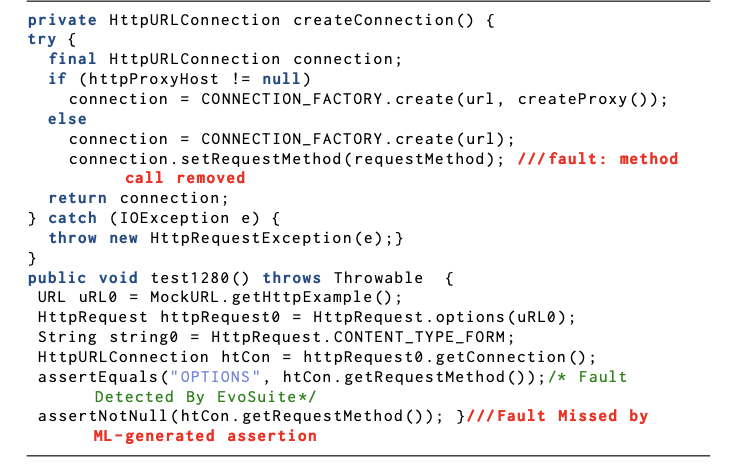
Code coverage is used by millions of developers in thousands of organizations on a daily basis. Despite this popularity, code coverage has well-understood limitations demonstrated by the software engineering research community, such as not providing enough insight into test oracles’ quality. In this research, we compute coverage gaps, a metric to detect the undertested program structures by analyzing the existing test oracles. We then propose a lightweight intra-procedural flow-insensitive static analysis technique that uses the system under test (SUT) and the coverage gaps as inputs to recommend actionable feedback to the developers to complement the test suite with additional test oracles, which demonstrated to improve the fault-detection effectiveness of the test suite.
Details: [paper (ICSE’23)] [artifact] [talk] [poster]
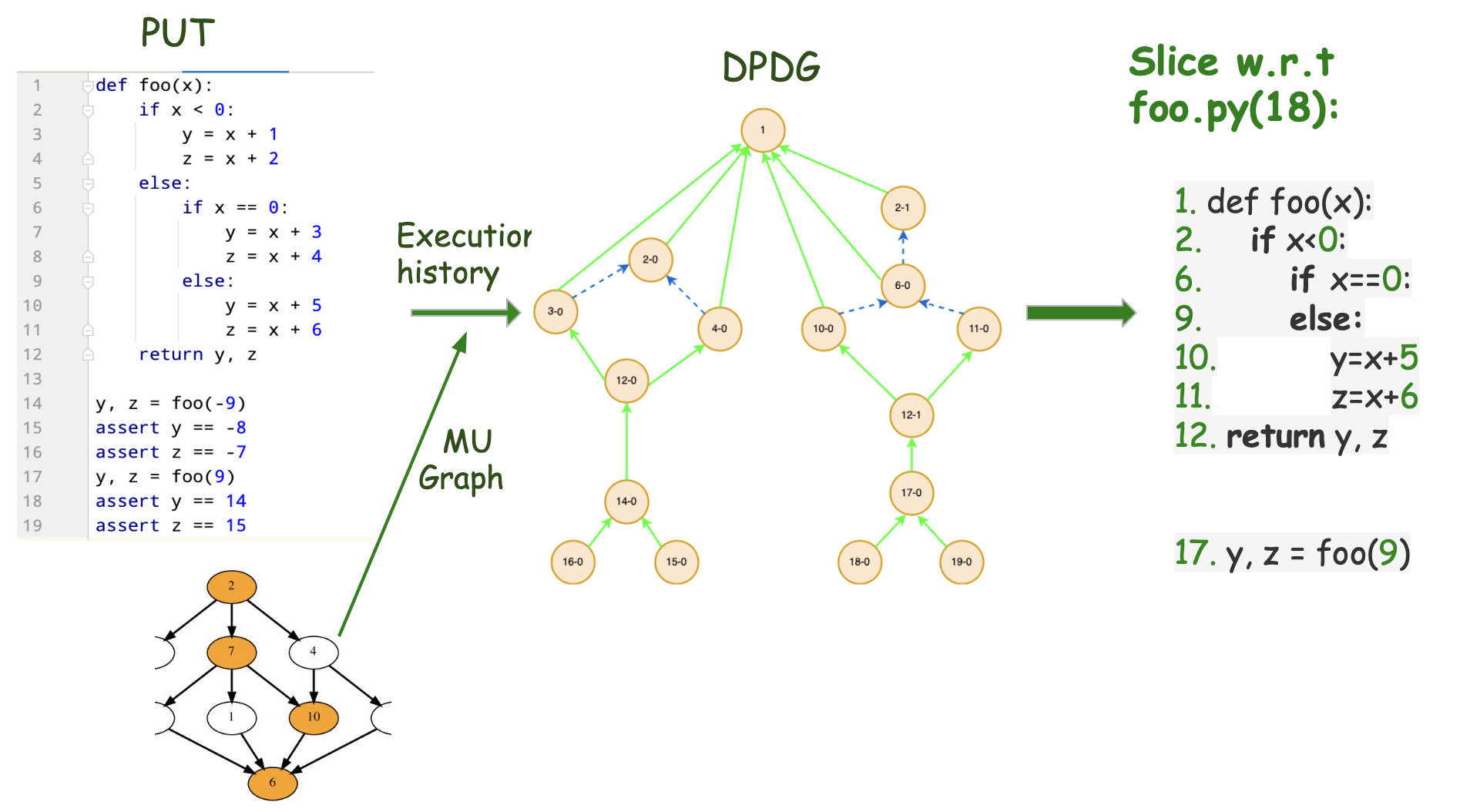
Dynamic dependency analysis is a heavily used program analysis technique in software engineering. Plenty of static slicing tools are available to support different languages. However, only a few good tools are available for Java program language, such as JavaSlicer, and Slicer4j. I developed a language-agnostic dynamic program slicing tool during my summer’22 internship at the AWS Code Guru team that supports Java, Python, and JavaScript. This tool implements the classic dynamic slicing algorithm proposed by Agrawal and Horgan, 1990. First, execution trace and muGraph (an extended abstract syntax tree) are used to construct a dynamic program dependency graph (DPDG). Next, from the DPDG, a breadth-first traversal is performed w.r.t the slicing criterion to compute the dynamic slice.

This tool operates on LLVM IR and instruments the bitcode to insert additional instructions for recording execution traces. Variables in a program can be declared as symbolic/unknown, and once the program is executed on concrete inputs, symbolic constraints are generated and stored in a file. Generated symbolic constraints can be used to perform dynamic symbolic execution or to compute input domain coverage using quantifcation.
Details: GitHub
